PIC AVR 工作室->TopPage->資料倉庫->8dotフォントの資料
マイコンで8ドットフォントを使うための資料
容量の少ないマイコンだって漢字表示をしたい…だけどTTFはおろか16×16ドットフォントでも容量的にキビシイ。 でも頑張ってマイコンでも自由自在に漢字を表示してみたい。そんな妄想が以前からありました。
というわけで、美咲フォントに白羽の矢を立ててこれをマイコンで扱えるようにするための調査をしてみました。 その調査結果を纏めておきます。
美咲フォントは↓こういうフォントです。

微妙ではありますが、なんとなく漢字として読めますよね?
美咲フォントと恵梨沙フォント
生い立ち
フリーで公開されているフォントにはイロイロあるんですが、片っ端から情報整理する手間は省くとして、 数多有るフォントの中から情報量(バイト数)は減らしつつ、それなりに読める文字として恵梨沙フォントと美咲フォントに白羽の矢を立てました。 これらは1文字が8×8ドットで構成されるフォントなので、容量・データ単位などの観点からマイコンでハンドリングするのに何かと便利だからです。
これら2つのフォントに関する解説は 美咲フォントの公式ページに詳しく書いてあるのですが、私なりの理解を簡単に纏めておきます。
フリーの8ドットフォントとして公開されているフォントの代表としてまず挙げられるのは恵梨沙フォントです。 恵梨沙フォントは8×8ドットのフォントで、PC-E500系ポケコンを日本語化する目的で作られたという経緯があるらしいのですが、 8×8ドットの領域をギリギリまで使っているため、文字間を適当なドット数空けて表示しないと文字と文字がくっ付いてしまうという欠点があったようです。
この欠点を解消するために、文字部分を7×7ドットに押し込んで右側と下側の1列にそれぞれ余白を設けたのが美咲フォントで、 そのため美咲フォントなら文字間に余白を作らなくても文字同士がくっ付かず、読みやすい表示が可能となるようです。
さすがに漢字を7×7ドットに押し込んでいるために1文字1文字を眺めると可読性には少々難があるのですが、 こちらのページの液晶表示した美咲フォントの例を眺めてみるに、 コンテキストから字を判別することは充分可能な雰囲気です。
美咲フォントについて
美咲フォントはJISの第1水準、第2水準両方がもりこまれています。大抵の文字は表示できると考えてよいでしょう。 また、美咲フォントはゴシック体、明朝体が用意されているので、どちらか一方、もしくはマイコン側の容量が許せば両方とも使うことも可能です。
また、商用・非商用問わず自由に使ってよいとされています。 ライセンスの詳細は公式サイトをご参照ください。 ありがたいことです。南無南無。
容量が小さく、8ドットフォントで組まれており、可読性もそれなりに確保できている美咲フォントならマイコンにピッタリと考え、 この美咲フォントをマイコンで取り扱うための方法を検討してみました。
作戦
フォーマットについて
美咲フォントの生い立ちはそんな経緯らしいので、ファイルフォーマットはwindowsのdos窓などで使うfnt形式等になっているようです。 fnt形式のフォーマットを私が知ってればそのまま使えばいいのかも知れないけど、調べるのが面倒とかイロイロな理由で別案を考えることにします。
公式ページではpng形式の画像ファイルも公開されています。この画像ファイルから1ドット1ドットデータをサルベージしてしまおうという作戦です。 それならマイコンに登載する際にデータの形式を好きなように弄れるので。
例えば、表示器の仕様によって書き込む際のドットの並びが縦だったり横だったりするし、Msb、Lsbを右にするか左にするか (もしくは上にするか下にするか)といったことも環境に合わせてフルカスタマイズ可能なので、 いっそ各組み込み環境の要件にあわせて使いやすい形式に変形してしまいたい。 そうすればフォントデータをメモリから読み出してそのまま表示器にI/F可能となり、処理負荷の観点でも有利に出来るはず…と。
というわけで、画像データから1ドットずつ読み出しをして、各表示器・各言語向けのソースプログラム的なデータ形式に換えちゃうことを考えて行きます。
フォントデータのサルベージ方法
フォントデータを何らかの方法でサルベージして、さらにそれを各種言語で使いやすい形式(テキストファイル)に変換する必要があります。
FNT形式ファイルのフォーマットを解析したり、それを色んな形式に変換したりするのは面倒なので、 png形式の画像ファイルを元に1ドット1ドットずつ読み出して、それに適当な変換を加えて、 アセンブラ(アセンブリ言語)やC言語など各種言語プログラムからインクルードして簡単に組み込めるようなテキストファイルに変換しようと思います。
C言語なら文字(char型)配列にしてみたり、AVR用アセンブラなら「.DB」形式のバイト列にしてしまったり。そういう変換を行います。
画像ファイルを1ドット1ドット読み取ったりテキストファイルを吐き出したりする処理は大抵の言語で処理可能だと思いますが、 とりあえず扱いが簡単そうで、かつ無料で使える言語が良いだろうと考え、今回は「HSP」を使ってみることにしました。 処理内容自体は大したモンじゃ無いので、どんな言語にも移植は簡単かと思います。
ただ、現時点のHSPではpng形式の画像ファイルを直接扱うことが出来ないので、適当な画像処理ソフトで一旦bmpなどに変換し、 それを入力することにします。私の場合は愛用のJTrim.exeを使用しました。適宜ご愛用のソフトを使ってbmp形式に変形してください。
HSPについては詳説しないので、VECTORなどでダウンロードして使ってください。
各種環境用のHSP用スクリプト
各種言語用のインクルードファイルを作成するにあたり、準備としてまずはpng画像ファイルをbmp形式に変換しておいてください。 変換するツールは上述の通り何でも構いません。
AVRのアセンブラ用への変換
AVRのアセンブラ用に変換するスクリプトを考えてみます。
AVRのアセンブラで漢字フォントデータを登載するとしたら、プログラムメモリ上(フラッシュメモリ上)に配置するのが順当でしょう。 コードセグメント、いわゆる「.cseg」上です。.cseg上で「.db」(バイトデータの定義)を行う様にしてしまえばincludeが出来るようになります。
フォントの情報量はバイトデータとしておよそ60KB前後に至るので、at-mega128などの大容量シリーズじゃないとキビシイかも。 処理内容によっては64KB版のAVRでも扱える可能性は有りますが…
で、HSPのプログラムを書くにあたっての方向性ですが、アセンブラ用なので処理速度上クリティカルな用途ということになるでしょう。 ということで、NTSCのビデオ出力用途程度にも耐えられるデータ定義・データ構造としたいと思います。ビデオ出力といえば、 データ形式は左から右へのビット列というのが一番処理負荷上有利でしょう。それを前提においてHSPのスクリプトを書いてみます。
例によって、不等号、ダブルコーテーション、アンパサンドは全角に替えてあります。半角に戻して使ってください。(以下同文)
screen 0,752,752,,0,0
picload ”misaki.bmp”
dim hx,16
hx(0) = ”0”
hx(1) = ”1”
hx(2) = ”2”
hx(3) = ”3”
hx(4) = ”4”
hx(5) = ”5”
hx(6) = ”6”
hx(7) = ”7”
hx(8) = ”8”
hx(9) = ”9”
hx(10) = ”A”
hx(11) = ”B”
hx(12) = ”C”
hx(13) = ”D”
hx(14) = ”E”
hx(15) = ”F”
notesel note1
for yy,0,84,1
for xx,0,94,1
cc = ” .db ”
for dy,0,8,1
pp = 0
for dx,0,8,1
x = xx * 8 + dx
y = yy * 8 + dy
pget x,y
p1 = ginfo(16) ;R
p2 = ginfo(17) ;G
p3 = ginfo(18) ;B
if (p1<10)&(p2<10)&(p3<10) {
pp = pp + (1 << (7-dx))
}
color 255,0,0
pset x,y
next
ch = hx((pp and 0x0f0) / 0x10)
cl = hx(pp and 0x0f)
cc = cc + ”0x”+ ch + cl
if dy < 7 {
cc = cc + ”,”
}
next
cc = cc + ” ;” + (yy*84+xx)
noteadd cc
next
next
notesave ”misaki.inc”
gsel 0,-1
dialog ”process ended.”
実行すると「misaki.inc」というファイル名で以下の様なスクリプトファイルが出力されます。
.db 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00 ;0
.db 0x00,0x00,0x00,0x00,0x00,0x80,0x40,0x00 ;1
.db 0x00,0x00,0x00,0x00,0x40,0xA0,0x40,0x00 ;2
.db 0x00,0x00,0x00,0x00,0xC0,0x40,0x80,0x00 ;3
(中略)
.db 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00 ;7063
.db 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00 ;7064
.db 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00 ;7065
こいつをアセンブラプログラムの.cseg上でインクルードしてあげればよいわけです。
補足を。
HSPは16進数関係の関数(VBで言うhex関数みたいなもの)が登載されていないようなので、ベタで変換掛けないといけません。 ちょっと面倒ですねぇ…。
あとは簡単。1文字分(8×8=64ドット分)毎に画像を切り出して、横方向8ドットを1バイトにまとめて16進数表示で表示。 それを縦8ライン分まとめて1文字分としています。1文字分は8バイトに相当するわけです。
AVRのアセンブリ言語用に編集出力しているので、アセンブラソースから普通にincludeすれば使えます。 一応、at-mega128用のテストプログラムでアセンブルしてみて大丈夫そうな結果を得ました。 他のマイコンを使っている方は適宜手直しして使ってください。
文字の左がMsb、右がLsbになってます。この8バイトが一組で出力ファイル上1行分に相当します。
ちなみに pp = pp + (1 << (7-dx))のところをちょっと変えれば左右逆向きにできます。
インテルhex形式ファイルへの変換
インテルのhex形式ファイルに変換してみることにします。hex形式ならそのままI2CのEEPROMなどに直接書き込みが出来るので、 容量の小さいマイコンでも外部に漢字ROMとして実装することも可能になります。60KBちょっとの容量になるので、 64KBタイプ(512Kbitタイプ)以上のEEPROMが必要になります。
マイコンに接続する表示装置に合わせて2つほど実装方法を考えてみました。1バイトに格納するビット列を縦に切り出すか、 それとも横に切り出すか…といった観点です。SG12864互換の液晶ディスプレーの場合VRAMのメモリ配置は上がLsb下がMsbの縦並びで、 横を8ライン一組で1文字としておくと表示しやすいので、まずはこの並びにならってみます。左が1バイト目、右が8バイト目の並びです。
;;;;;; misaki font BMP to intel HEX (vertical) ;;;;;;
;;;;;; initialize ;;;;;;
screen 0,752,752,,0,0
picload ”misaki.bmp”
dim hx,16
hx(0) = ”0”
hx(1) = ”1”
hx(2) = ”2”
hx(3) = ”3”
hx(4) = ”4”
hx(5) = ”5”
hx(6) = ”6”
hx(7) = ”7”
hx(8) = ”8”
hx(9) = ”9”
hx(10) = ”A”
hx(11) = ”B”
hx(12) = ”C”
hx(13) = ”D”
hx(14) = ”E”
hx(15) = ”F”
notesel note1
;;;;;; main logic ;;;;;;
;;;;;; editing and outputing data records ;;;;;;
for yy,0,84,1
for xx,0,94,1
;initialize a line
cc = ”:08” ; set fixed char and data length
sum = 0 ; clear chech sum
;;;;;; calc offset add ;;;;;;
off_add = (yy * 94 + xx) * 8
off_h = (off_add & 0xff00) / 0x100
off_l = off_add \ 0x100
;;;;;; calc sum without data ;;;;;;
sum = sum + 0x08 + off_h + off_l
;;;;;; conv offset into hex ;;;;;;
num = off_h ;high byte of offset
gosub *num2hex
cc = cc + refstr
num = off_l ;low byte ob offset
gosub *num2hex
cc = cc + refstr
;;;;;; record type ;;;;;;
cc = cc + ”00” ;00=data record
;;;;;; loop while 1 char ;;;;;;
for dx,0,8,1
pp = 0 ;clear 8 dots sum
;;;;;; loop while 8 dots ;;;;;;
for dy,0,8,1
;;;;;; calc data ;;;;;;
x = xx * 8 + dx
y = yy * 8 + dy
pget x,y
p1 = ginfo(16) ;R
p2 = ginfo(17) ;G
p3 = ginfo(18) ;B
if (p1<10)&(p2<10)&(p3<10) {
;add to 8 dots sum
pp = pp + (1 << dy)
}
;fill up a char with a red box
color 255,0,0
pset x,y
next
;add to sum
sum = sum + pp
;conv to hex
num = pp
gosub *num2hex
cc = cc + refstr
next
;;;;;; calc check sum ;;;;;;
;2's complement
sum2 = (0x20000 - sum) and 0xff
;conv into hex
num = sum2
gosub *num2hex
cc = cc + refstr
;;;;;; outputting a line ;;;;;;
noteadd cc
next
next
;;;;;; outputting end record ;;;;;;
noteadd ”:00000001FF”
;;;;;; close file ;;;;;;
notesave ”misaki_v.hex”
gsel 0,-1
;;;;;; program end ;;;;;;
dialog ”process ended.”
end 0
;;;;;; sub routine ;;;;;;
;;;;;; convert num into hex ;;;;;;
*num2hex
hexh = hx((num and 0x0f0) / 0x10)
hexl = hx(num and 0x0f)
hexhl = hexh + hexl
;return a value through refstr
return hexhl
実行すると以下のようにインテルhex形式に整形されたファイルが出力されます。 1行あたりに8バイト分のデータ+アドレスやチェックサム等を収録しています。
:080000000000000000000000F8 :08000800204000000000000090 :08001000205020000000000058 (中略) :08F6A80000000000000000005A :08F6B000000000000000000052 :08F6B80000000000000000004A :00000001FF
次に、同じhex形式でもビットの並びが横方向のタイプも作っておきます。さっきのアセンブラと違って左がLsb右がMsbになってます。

;;;;;; misaki font BMP to intel HEX (horizontal) ;;;;;;
;;;;;; initialize ;;;;;;
screen 0,752,752,,0,0
picload ”misaki.bmp”
dim hx,16
hx(0) = ”0”
hx(1) = ”1”
hx(2) = ”2”
hx(3) = ”3”
hx(4) = ”4”
hx(5) = ”5”
hx(6) = ”6”
hx(7) = ”7”
hx(8) = ”8”
hx(9) = ”9”
hx(10) = ”A”
hx(11) = ”B”
hx(12) = ”C”
hx(13) = ”D”
hx(14) = ”E”
hx(15) = ”F”
notesel note1
;;;;;; main logic ;;;;;;
;;;;;; editing and outputing data records ;;;;;;
for yy,0,84,1
for xx,0,94,1
;initialize a line
cc = ”:08” ; set fixed char and data length
sum = 0 ; clear chech sum
;;;;;; calc offset add ;;;;;;
off_add = (yy * 94 + xx) * 8
off_h = (off_add & 0xff00) / 0x100
off_l = off_add \ 0x100
;;;;;; calc sum without data ;;;;;;
sum = sum + 0x08 + off_h + off_l
;;;;;; conv offset into hex ;;;;;;
num = off_h ;high byte of offset
gosub *num2hex
cc = cc + refstr
num = off_l ;low byte ob offset
gosub *num2hex
cc = cc + refstr
;;;;;; record type ;;;;;;
cc = cc + ”00” ;00=data record
;;;;;; loop while 1 char ;;;;;;
for dy,0,8,1
pp = 0 ;clear 8 dots sum
;;;;;; loop while 8 dots ;;;;;;
for dx,0,8,1
;;;;;; calc data ;;;;;;
x = xx * 8 + dx
y = yy * 8 + dy
pget x,y
p1 = ginfo(16) ;R
p2 = ginfo(17) ;G
p3 = ginfo(18) ;B
if (p1<10)&(p2<10)&(p3<10) {
;add to 8 dots sum
pp = pp + (1 << dx)
}
;fill up a char with a red box
color 255,0,0
pset x,y
next
;add to sum
sum = sum + pp
;conv to hex
num = pp
gosub *num2hex
cc = cc + refstr
next
;;;;;; calc check sum ;;;;;;
;2's complement
sum2 = (0x20000 - sum) and 0xff
;conv into hex
num = sum2
gosub *num2hex
cc = cc + refstr
;;;;;; outputting a line ;;;;;;
noteadd cc
next
next
;;;;;; outputting end record ;;;;;;
noteadd ”:00000001FF”
;;;;;; close file ;;;;;;
notesave ”misaki_h.hex”
gsel 0,-1
;;;;;; program end ;;;;;;
dialog ”process ended.”
end 0
;;;;;; sub routine ;;;;;;
;;;;;; convert num into hex ;;;;;;
*num2hex
hexh = hx((num and 0x0f0) / 0x10)
hexl = hx(num and 0x0f)
hexhl = hexh + hexl
;return a value through refstr
return hexhl
どちらのhexファイルも、秋月PICライターなどでEEPROMに書き込みができます。
ビット合成処理の部分を pp = pp + (1 << (7-dx)) と書き換えれば左右の並びを逆にできます。
C言語用の配列定義文に変換
C言語の配列定義文に変換してみます。とりあえず一般的なC言語用の配列を出力する仕様にしておき、 あとは各言語環境などに合わせて修飾子などを指定するなどで配置先を変えて使ってください。
普通のマイコンであれば、登載している容量の関係からプログラムコードのエリアに展開させるのが常套手段でしょうか。 その辺の指定は同じC言語でも環境によって若干異なるでしょうから、そこまでは盛り込みません。 適宜環境に合わせて微調整してください。
;;;;;; misaki font BMP to include file for C ;;;;;;
;;;;;; initialize ;;;;;;
screen 0,752,752,,0,0
picload ”misaki.bmp”
dim hx,16
hx(0) = ”0”
hx(1) = ”1”
hx(2) = ”2”
hx(3) = ”3”
hx(4) = ”4”
hx(5) = ”5”
hx(6) = ”6”
hx(7) = ”7”
hx(8) = ”8”
hx(9) = ”9”
hx(10) = ”A”
hx(11) = ”B”
hx(12) = ”C”
hx(13) = ”D”
hx(14) = ”E”
hx(15) = ”F”
notesel note1
noteadd ”char misaki_char[][8]={”
;;;;;; main logic ;;;;;;
;;;;;; editing and outputing data records ;;;;;;
for yy,0,84,1
for xx,0,94,1
;initialize a line
cc = ” {” ; set fixed char and data length
;;;;;; loop while 1 char ;;;;;;
for dy,0,8,1
pp = 0
;;;;;; loop while 8 dots ;;;;;;
for dx,0,8,1
;;;;;; calc data ;;;;;;
x = xx * 8 + dx
y = yy * 8 + dy
pget x,y
p1 = ginfo(16) ;R
p2 = ginfo(17) ;G
p3 = ginfo(18) ;B
if (p1<10)&(p2<10)&(p3<10) {
;add to 8 dots sum
pp = pp + (1 << (7-dx))
}
;fill up a char with a red box
color 255,0,0
pset x,y
next
;conv to hex
num = pp
gosub *num2hex
cc = cc + ”0x” + refstr
if dy < 7 {
cc = cc + ”,”
}
else {
cc = cc + ”}”
}
next
if (yy < 83) or (xx <93) {
cc = cc + ”,”
}
;;;;;; outputting a line ;;;;;;
noteadd cc
next
next
;;;;;; outputting end record ;;;;;;
noteadd ”};”
;;;;;; close file ;;;;;;
notesave ”misaki_c.inc”
gsel 0,-1
;;;;;; program end ;;;;;;
dialog ”process ended.”
end 0
;;;;;; sub routine ;;;;;;
;;;;;; convert num into hex ;;;;;;
*num2hex
hexh = hx((num and 0x0f0) / 0x10)
hexl = hx(num and 0x0f)
hexhl = hexh + hexl
;return a value through refstr
return hexhl
データの並び順ですが、横8ドットを1バイトにして左がMsb右がLsbです。必要に応じて直して使ってください。
実行結果はこんな感じ。
char misaki_char[][8]={
{0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00},
{0x00,0x00,0x00,0x00,0x00,0x80,0x40,0x00},
{0x00,0x00,0x00,0x00,0x40,0xA0,0x40,0x00},
(中略)
{0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00},
{0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00},
{0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00}
};
試しにAVR用のGCC(WIN-AVR)に取り込んでコンパイルしてみました。
const char misaki_char[][8] PROGMEM
って指定をして「フラッシュ領域」に配置してみたところ、コンパイラ仕様に抵触してエラーとなりました。
その制約事項はブログに纏めておいたのでそちらをご参照ください。 要は、1個の配列で定義が可能なサイズをオーバーしたということです。 回避方法の一案をブログに纏めてあります。
その他言語
以上、各スクリプトは使いまわしが簡単にできるので各種言語用に作り直すのは造作無いでしょう。適当に使いまわしてください。 ちなみにHSPって画像ファイルやテキストファイルの扱いは簡単なんだけど、16進数関係の関数やビット処理が弱いので、 他の言語に移行した方がいいかもしれませんねぇ。
実際に使ってみよう
BMP画像に収録されたフォントデータをHSPのスクリプトを使って各種プログラムのソースに変形するところまでやりました。
さて、次はこれらを使って実際にスクリーン表示してみたいと思います。
作戦的なもの
ある程度妥当性の確認ができればいいやというレベルで考えているので、可能な限り手抜きをします。 まずは表示するためのデバイスですが、秋月でも売っているG-LCD(グラフィック液晶表示モジュール) SG12864Aならまさにビットマップ表示のためのデバイスなので、深く考えずにこれを使ってみます。 このSG12864Aはマイコンと20ピンのインターフェースで接続し、マイコンからコマンドやビットマップデータを送信して使います。
これを扱うにあたって注意が必要なのは、まず制御方法についてです。SG12864Aの初期化や各種設定を行うためには、 マイコンからSG12864Aに向かって各種コマンド等を送る必要がありますが、面倒くさいので手を抜くことを考えます。
ふとarduinoの公式サイトを眺めてみると、SG12864Aもそのまま利用できるライブラリが公開されているので、 マイコンボードにはarduinoを、言語はarduino言語(C言語+αといった感じの言語です)を、 表示装置にはSG12864Aを使用して、手抜きでサクッと動作確認を済ますことにします。
データ形式について
もう一つ注意するのは、SG12864Aに送信する時のビットマップデータの並びのことです。 SG12864Aに限らず、ビデオRAMをアクセスする際にはそのビデオRAMがどの様なならびでデータを保持しているのかということが影響します。
SG12864Aをarduino用ライブラリを使ってアクセスする際も、この点についてライブラリのi/f仕様が大きく影響を受けています。 具体的には、GLCD.DrawBitmap(ビットマップ, x座標,y座標,色); というメソッドを使ってアクセスする際のビットマップデータに、 どの様な形式の引数を渡せばいいかというお話です。このメソッドの詳細はarduino公式サイトをご覧ください。
さて、このメソッドのビットマップに8×8ドットの漢字データをどのように与えればいいかというお話。
uint8-t型というarduino独自の符号なし8ビット整数の配列(のポインタ)を引き渡すことになっています。 この配列の先頭2バイトはそれぞれ横幅、高さのドット数を指定することになっており、 その後ろにビットマップデータをズラズラと格納することになっています。
その際のビットの並びですが、言葉だけで示すのは難しいのでまずはマンガを描いてみます。
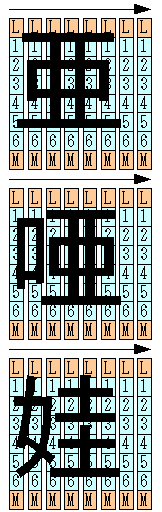
この図の見方について簡単な解説を。
図の左上から縦に8ドットを一まとめにして1バイトのデータとします。次にその1行右隣に移って同じように縦8ドットを1バイトに纏めます。 このように1文字分(=8ライン)を一まとめにして1バイト分8バイトのデータが出来上がります。
例えば「亜」という字なら 0x5D,0x55,0x7F,0x55,0x7F,0x55,0x5D,0x00, という8バイトのデータが出来上がるわけです。 (お時間有る方は、この8バイトをビット列に戻して眺めてみてください)
図を見ると、「亜」という字が左上に片寄っているかと思いますが、それが美咲フォントの肝となる部分です。 つまり右端1列と下一列を空白とし、残りの7×7ドットで1文字を構成しているので、 文字と文字をぴったりくっつけても、文字同士がゴチャゴチャにならないっていうわけですね。
さて、複数文字を一度にたくさん表示するには、この8バイトのデータを必要なだけズラズラ並べればいいというわけです。 その際、横幅と高さのドット数は配列の先頭に1個だけあればよく、その後ろは8バイトのビットマップデータがズラズラ並んでいるというわけ。
実際に表示してみましょう
文章で表しても解り難いと思いますので、arduino用のスケッチを実際に書いてみます。 (例によって不等号は全角に替えてあるので半角に戻してください)
#include <ks0108.h> // library header
#include <Arial14.h> // font definition for 14 point Arial font.
#include "SystemFont5x7.h" // system font
static uint8_t kanji_sample[] PROGMEM = {
8, // width
64, // height
0x5D,0x55,0x7F,0x55,0x7F,0x55,0x5D,0x00,
0x1E,0x12,0x5D,0x7F,0x55,0x7F,0x5D,0x00,
0x44,0x5C,0x37,0x2C,0x5A,0x7F,0x5A,0x00,
0x7F,0x25,0x1B,0x1D,0x15,0x5D,0x7F,0x00,
0x22,0x2E,0x7A,0x4B,0x1A,0x2E,0x52,0x00,
0x4D,0x57,0x2D,0x57,0x3D,0x57,0x4D,0x00,
0x52,0x7F,0x0A,0x56,0x5D,0x34,0x56,0x00,
0x44,0x5C,0x37,0x2C,0x76,0x55,0x76,0x00
};
void setup(){
GLCD.Init(NON_INVERTED); // initialise the library, non inverted turns on written pixels
GLCD.ClearScreen();
GLCD.DrawBitmap(kanji_sample, 32,0, BLACK); //draw the bitmap at the given x,y position
}
void loop(){ // run over and over again
}
このスケッチ中に出てくるkanji_sampleという配列には「亜」「唖」「娃」「阿」「哀」「愛」「挨」「姶」 の8文字のデータ、 計64バイトだけを取り出したものです。そして横幅8ドット(1文字分)、高さ64ドット(8文字分)としているので、 このスケッチを実行してみると文字は縦一列にならんでこんな風になります。

このスケッチをちょっと弄って横幅を64ドット、高さを8ドットと指定しなおしてみると、何の問題も無く横一列の漢字が表示されることになります。
このように、8ドット単位ということで色々扱いがラクチンになるというのが美咲フォントを使うメリットの一つとして挙げられるかと思います。
さすがに潰れ気味のフォントですが、文脈(コンテキスト)をヒントにすればそれなりに読み取ることは可能な範疇でしょう。
もろもろの注意事項
arduino+SG12864Aの場合のHSPスクリプトについて
arduinoとSG12864Aを組み合わせて使った場合、ビットの並び、バイトの並びは、実は上記のHSPスクリプトでは対応してません。
なので、この組み合わせに似つかわしいHSPスクリプトも作ってみました。先ほどのarduino用スケッチ中の定義はこの実行結果を使ったモノです。
;;;;;; misaki font BMP to include file for C ;;;;;;
;;;;;; initialize ;;;;;;
screen 0,752,752,,0,0
picload "misaki.bmp"
dim hx,16
hx(0) = "0"
hx(1) = "1"
hx(2) = "2"
hx(3) = "3"
hx(4) = "4"
hx(5) = "5"
hx(6) = "6"
hx(7) = "7"
hx(8) = "8"
hx(9) = "9"
hx(10) = "A"
hx(11) = "B"
hx(12) = "C"
hx(13) = "D"
hx(14) = "E"
hx(15) = "F"
notesel note1
noteadd "char misaki_char[][8]={"
;;;;;; main logic ;;;;;;
;;;;;; editing and outputing data records ;;;;;;
for yy,0,84,1
for xx,0,94,1
;initialize a line
cc = " {" ; set fixed char and data length
;;;;;; loop while 1 char ;;;;;;
for dx,0,8,1
pp = 0
;;;;;; loop while 8 dots ;;;;;;
for dy,0,8,1
;;;;;; calc data ;;;;;;
x = xx * 8 + dx
y = yy * 8 + dy
pget x,y
p1 = ginfo(16) ;R
p2 = ginfo(17) ;G
p3 = ginfo(18) ;B
if (p1<10)&(p2<10)&(p3<10) {
;add to 8 dots sum
pp = pp + (1 << dy)
}
;fill up a char with a red box
color 255,0,0
pset x,y
next
;conv to hex
num = pp
gosub *num2hex
cc = cc + "0x" + refstr
if dx < 7 {
cc = cc + ","
}
else {
cc = cc + "}"
}
next
if (yy < 83) or (xx <93) {
cc = cc + ","
}
;;;;;; outputting a line ;;;;;;
noteadd cc
next
next
;;;;;; outputting end record ;;;;;;
noteadd "};"
;;;;;; close file ;;;;;;
notesave "misaki_v_c.inc"
gsel 0,-1
;;;;;; program end ;;;;;;
dialog "process ended."
end 0
;;;;;; sub routine ;;;;;;
;;;;;; convert num into hex ;;;;;;
*num2hex
hexh = hx((num and 0x0f0) / 0x10)
hexl = hx(num and 0x0f)
hexhl = hexh + hexl
;return a value through refstr
return hexhl
で、このスクリプトを実行するとmisaki_v_c.incという名前のファイルが出来て、その中身は
char misaki_char[][8]={
{0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00},
{0x20,0x40,0x00,0x00,0x00,0x00,0x00,0x00},
{0x20,0x50,0x20,0x00,0x00,0x00,0x00,0x00},
{0x50,0x30,0x00,0x00,0x00,0x00,0x00,0x00},
{0x60,0x60,0x00,0x00,0x00,0x00,0x00,0x00},
{0x00,0x00,0x18,0x18,0x00,0x00,0x00,0x00},
{0x00,0x00,0x36,0x36,0x00,0x00,0x00,0x00},
{0x00,0x00,0x56,0x36,0x00,0x00,0x00,0x00},
(中略)
{0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00},
{0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00}
};
こんな感じになります。
これ全体ではメモリ量として60KB前後となってしまいarduinoには入りきらないので、 表示を行う一部分だけを切り出し、またこの2次配列状態のままではarduinoのG-LCDライブラリに渡せないので、 1次配列に少々手直ししたのが先ほどのスケッチ中にでてきたこの部分
static uint8_t kanji_sample[] PROGMEM = {
8, // width
64, // height
0x5D,0x55,0x7F,0x55,0x7F,0x55,0x5D,0x00,
0x1E,0x12,0x5D,0x7F,0x55,0x7F,0x5D,0x00,
0x44,0x5C,0x37,0x2C,0x5A,0x7F,0x5A,0x00,
0x7F,0x25,0x1B,0x1D,0x15,0x5D,0x7F,0x00,
0x22,0x2E,0x7A,0x4B,0x1A,0x2E,0x52,0x00,
0x4D,0x57,0x2D,0x57,0x3D,0x57,0x4D,0x00,
0x52,0x7F,0x0A,0x56,0x5D,0x34,0x56,0x00,
0x44,0x5C,0x37,0x2C,0x76,0x55,0x76,0x00
};
というわけでした。ちなみにこの配列は1行が漢字1文字に相当していて、8文字分のビットマップイメージを配列に収めているわけです。 配列の先頭に8とか64とかという数値が記載されていますが、8と言うのは横方向のドット数、 64と言うのはビットイメージ分の要素数です。arduinoのG-LCDライブラリに盛り込まれているDrawBitmapメソッドでこの配列を使うと、 8と64という数値を元にビットイメージを画面上に表示してくれます。扱いが簡単なのはさすがarduino。
AVR用のC言語系で使用する場合の制限事項
今回はとりあえず表示できるかどうかの確認ということでarduinoを使ったため、ごく一部の漢字しか表示できませんでしたが、 表示自体は上手くできることが判りました。
一方、arduinoといえば、AVR用のC言語系コンパイラであるgccがベースになっています。 gccでは配列定義の際に言語仕様上の制限があり、使用の際に注意が必要です。
AVRのgccでは、配列などのオブジェクト1個あたりで32KB以内、もしくは要素数が32K個(32767個) に収まっていなければならないという制約があります。これは配列を管理するインデックスが2バイト幅の符号付整数で管理されているためで、 バイト数、もしくはインデックスの数が15ビットの整数までしか扱えないことに起因します。
構造体の中に、複数に分割した配列を格納するという手もアウトです。配列1組みあたりのサイズは32KB以下に押さえることができますが、 構造体全体のインデックス数はやはり32K個を超えてしまうことになるからです。 この制約に関するお話はブログ に記載してあるのでそちらをご参照ください。
arduinoの場合は、JIS1、JIS2の漢字データを取り込むとなると、容量が足りないだけでなく、この制約にも抵触します。 そのため今回のサンプルスケッチも漢字データの一部分しか取り込みませんでした。
同じAVRでも、アセンブラやその他の言語となると話は別ですし、AVR以外のマイコンの場合はやはりこの制約とは無関係となります。
マイコンによってはオンチップROMに全部登載することも可能でしょう。 AVRの場合は大容量タイプでもオンチップに載せるとなるとgccでは制約が出るため、配列をいくつかに分割するか、 外付けのEEPROMに格納してI2Cで読み出すなどの工夫が必要となるかと思います。
適宜、使う環境に合わせて多少のアレンジが必要になるかと思います。
まとめ
HSPを使って美咲フォントのグラフィックデータから各種言語用のビットマップ定義のスクリプトを作成することができました。 あとはこの出力されたスクリプトを各種言語用に読み込むなりすれば漢字の表示が比較的容易に出来るようになるかと思います。
今後、I2C接続のEEPROMに内蔵して漢字表示したり、マイコン内に登載したりして漢字表示をしたいとか思ってますが、 とりあえず当初の目的は見えたのでこのページはひとまず完結にします。
何かメモとして残しておきたいことが出来たらまた追記したいと思います。
… 続きます …
![]()





